- VMware
- 01 May 2024 at 07:17 UTC
-


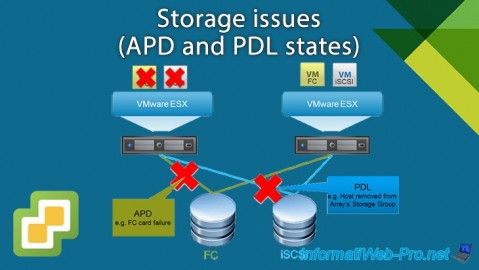
When you use shared storage in a VMware vSphere virtual infrastructure, which is generally the case in businesses, it may happen that part or all of it becomes inaccessible for one or more VMware ESXi hosts depending on the case. .
In this case, different states may occur: All-Paths-Down (APD) or Permanent Device Loss (PDL).
- All-Paths-Down (APD)
- Permanent Device Loss (PDL)
- Generate an APD state (demonstration)
- Generate a PDL state (demonstration)
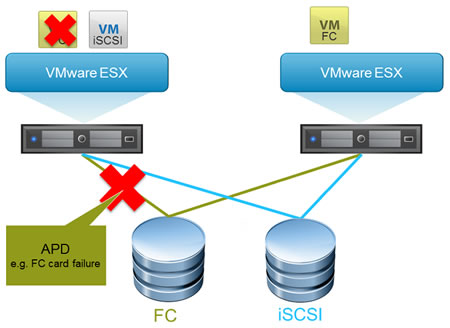
1. All-Paths-Down (APD)
When a storage device is inaccessible for a certain period of time, its state changes to APD (All-Paths-Down).
The APD state is considered temporary, so your VMware ESXi host expects this storage device to be accessible again soon. The host will therefore continue to send commands to reconnect this storage device.
However, after a certain delay (140 seconds, by default), the state of this storage device will change to PDL (Permanent Device Loss). In fact, this delay is deliberately longer than the delay necessary for storage devices normally to recover the connection.
PDL status meaning this device has been permanently lost.
Note: the APD timeout can be modified using the advanced setting "Misc.APDTimeout".
APD condition can occur due to:
- a faulty switch.
Ex: an FC (Fiber Channel) switch or an Ethernet switch in the case of iSCSI storage. - a faulty storage controller.
Ex: an FC storage controller or an Ethernet network interface in the case of iSCSI. - a faulty or accidentally unplugged storage cable.
Ex: an FC cable or an RJ45 cable for iSCSI.
Important : virtual machines will continue to respond even though the affected storage device and datastores are unavailable. So you can move them or turn them off manually.
Sources :
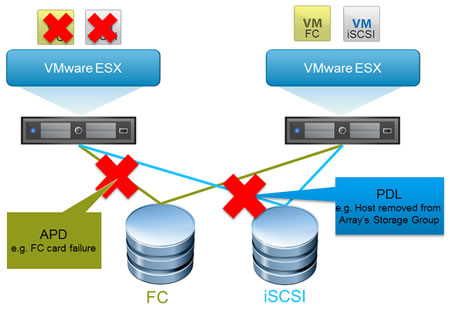
2. Permanent Device Loss (PDL)
When a storage device is permanently inaccessible, its status changes to PDL (Permanent Device Loss).
The PDL condition can occur because of:
- a storage device that was not previously detached under VMware vSphere before being removed from a storage array.
In the case of a PDL state, all paths for the storage device concerned are therefore displayed as dead.
Warning : you can only resolve a PDL state by powering off the affected virtual machines.
Which is not necessary in the case of an APD state.
Sources :
3. Generate an APD state (demonstration)
To be able to show you what happens under VMware vSphere in the case of an APD state, we will intentionally generate an APD state.
To do this, start the "TSM-SSH" service on a host with an iSCSI datastore.
Then, connect by SSH to this host using PuTTY (for example).
Authenticate as "root" and type the command below to see the end of the "vmkernel.log" in real time.
Bash
tail -f /var/log/vmkernel.log
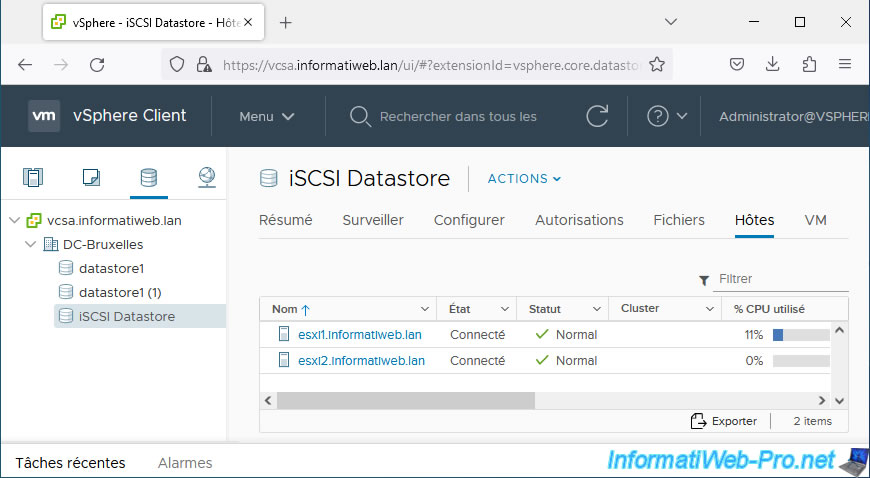
In our case, we have a datastore named "iSCSI Datastore" visible to our 2 hosts "esxi1" and "esxi2".
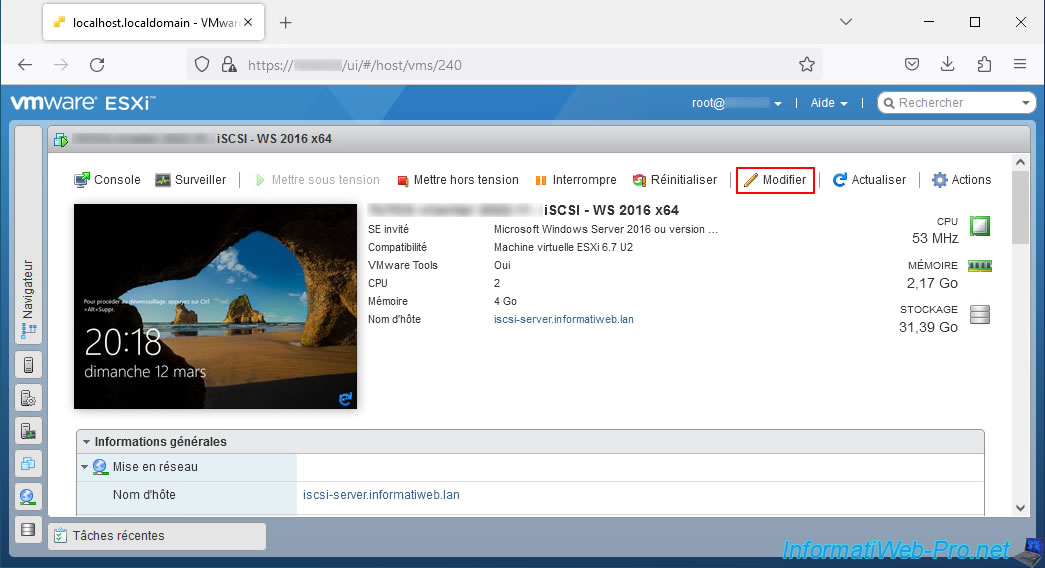
To cause an APD state (in the case of a lab), you simply cut off network access to the iSCSI server where the affected datastore is located.
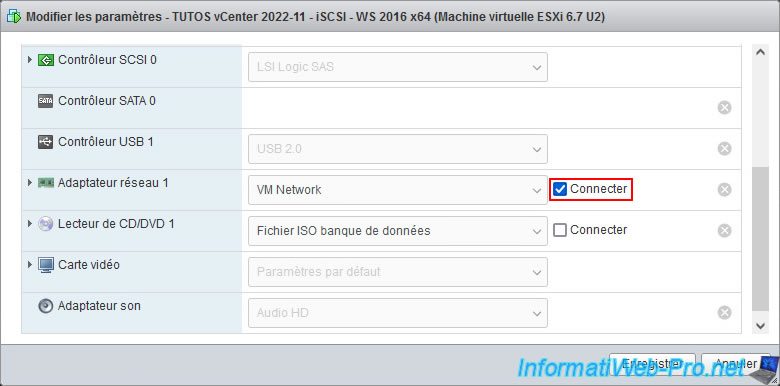
In our case, this iSCSI server runs on a hypervisor under VMware ESXi. Select this VM and click "Edit".
At the moment, the network adapter of this VM is connected.
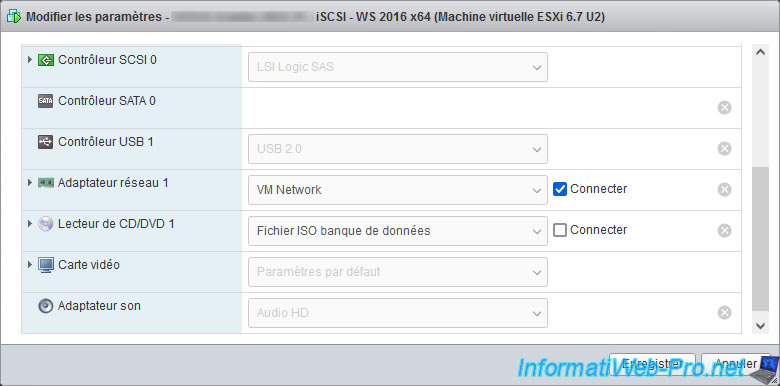
Uncheck the "Connect" box for this network adapter and click Save.
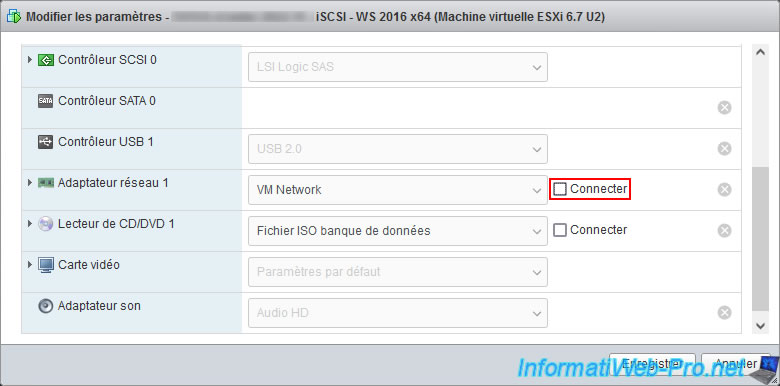
In SSH, you will see the keywords appear at one point: APD and All Paths Down.
Plain Text
2023-03-12T19:20:49.377Z cpu1:2097217)ScsiDevice: 8711: No Handlers registered! (naa.60003ff44dc75adcbb56fae32c5520eb)! 2023-03-12T19:20:49.377Z cpu1:2097217)ScsiDevice: 5982: Device state of naa.60003ff44dc75adcbb56fae32c5520eb set to APD_START; token num:1 2023-03-12T19:20:49.377Z cpu1:2097217)StorageApdHandler: 1203: APD start for 0x43035a6bd7b0 [naa.60003ff44dc75adcbb56fae32c5520eb] 2023-03-12T19:20:49.377Z cpu3:2097369)StorageApdHandler: 419: APD start event for 0x43035a6bd7b0 [naa.60003ff44dc75adcbb56fae32c5520eb] 2023-03-12T19:20:49.377Z cpu3:2097369)StorageApdHandlerEv: 110: Device or filesystem with identifier [naa.60003ff44dc75adcbb56fae32c5520eb] has entered the All Paths Down state.
Source : Storage device has entered the All Paths Down (APD) state.
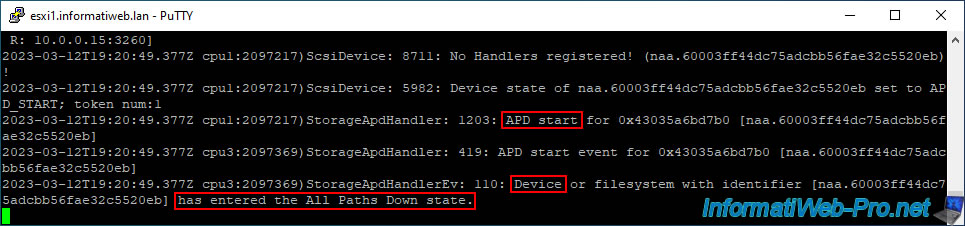
In the VMware vSphere Client, you will see that the status of your iSCSI datastore is "Inaccessible".
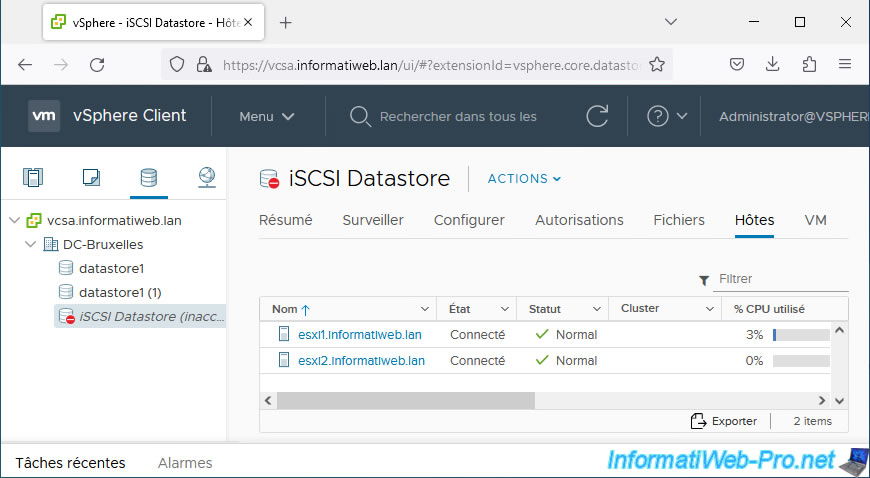
Select a host that this iSCSI datastore is connected to and go to: Configure -> Storage -> Storage Devices.
As you can see, the iSCSI disk affected by your iSCSI datastore is displayed grayed out and its operational status is "Dead or Error".
As explained previously, an ODA state is considered temporary. VMware vSphere therefore expects this issue to be resolved at some point.
To restore the situation, simply reconnect the network adapter of your iSCSI server.
As expected, VMware vSphere will automatically detect that the iSCSI disk is accessible again without issue.
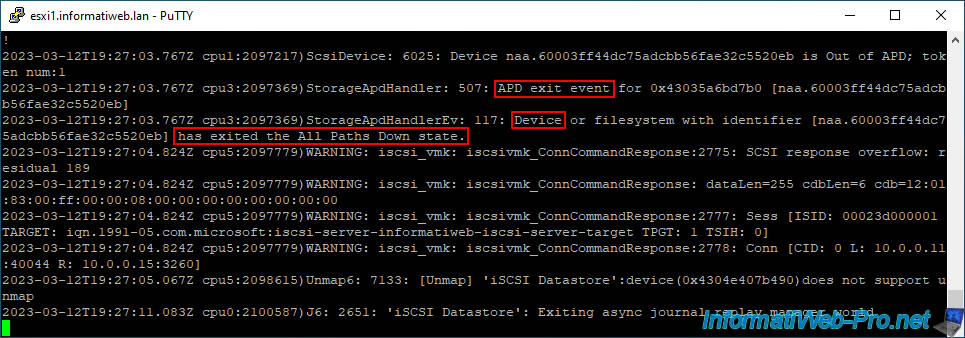
Still in the log file "/var/log/vmkernel.log", you will see this appear:
Plain Text
2023-03-12T19:27:03.767Z cpu1:2097217)ScsiDevice: 6025: Device naa.60003ff44dc75adcbb56fae32c5520eb is Out of APD; token num:1 2023-03-12T19:27:03.767Z cpu3:2097369)StorageApdHandler: 507: APD exit event for 0x43035a6bd7b0 [naa.60003ff44dc75adcbb56fae32c5520eb] 2023-03-12T19:27:03.767Z cpu3:2097369)StorageApdHandlerEv: 117: Device or filesystem with identifier [naa.60003ff44dc75adcbb56fae32c5520eb] has exited the All Paths Down state.
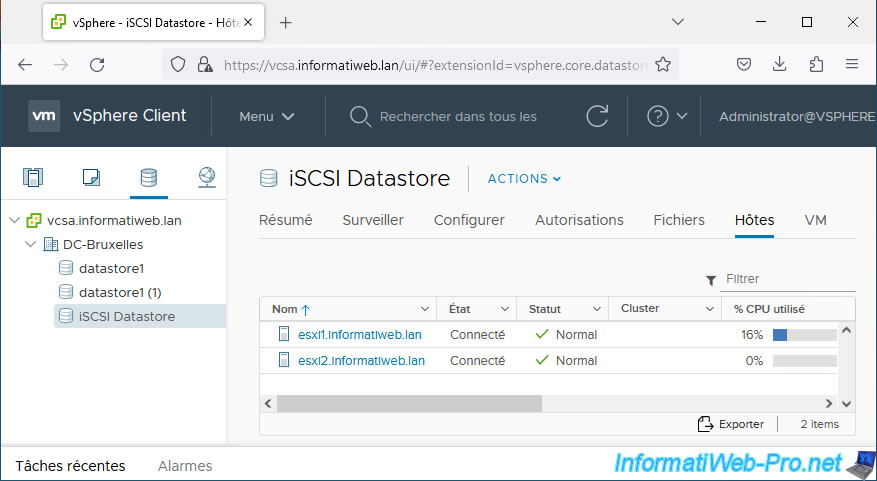
In the VMware vSphere Client, you will see that the error on your datastore has disappeared and that it is therefore accessible again.
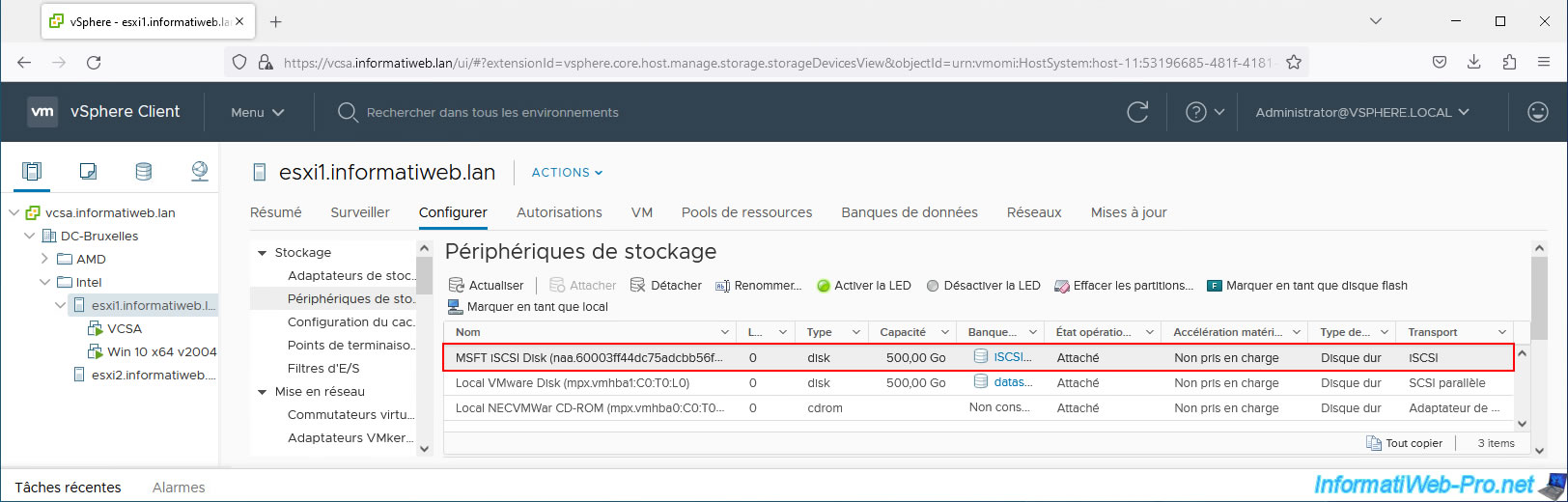
In the list of storage devices, the disk will again be displayed in black and not grayed out and its operational status will return to "Attached" instead of "Dead or error".
4. Generate a PDL state (demonstration)
Again as a demonstration, we will intentionally generate a PDL state.
To do this, we will reuse the same iSCSI disk with the same datastore.
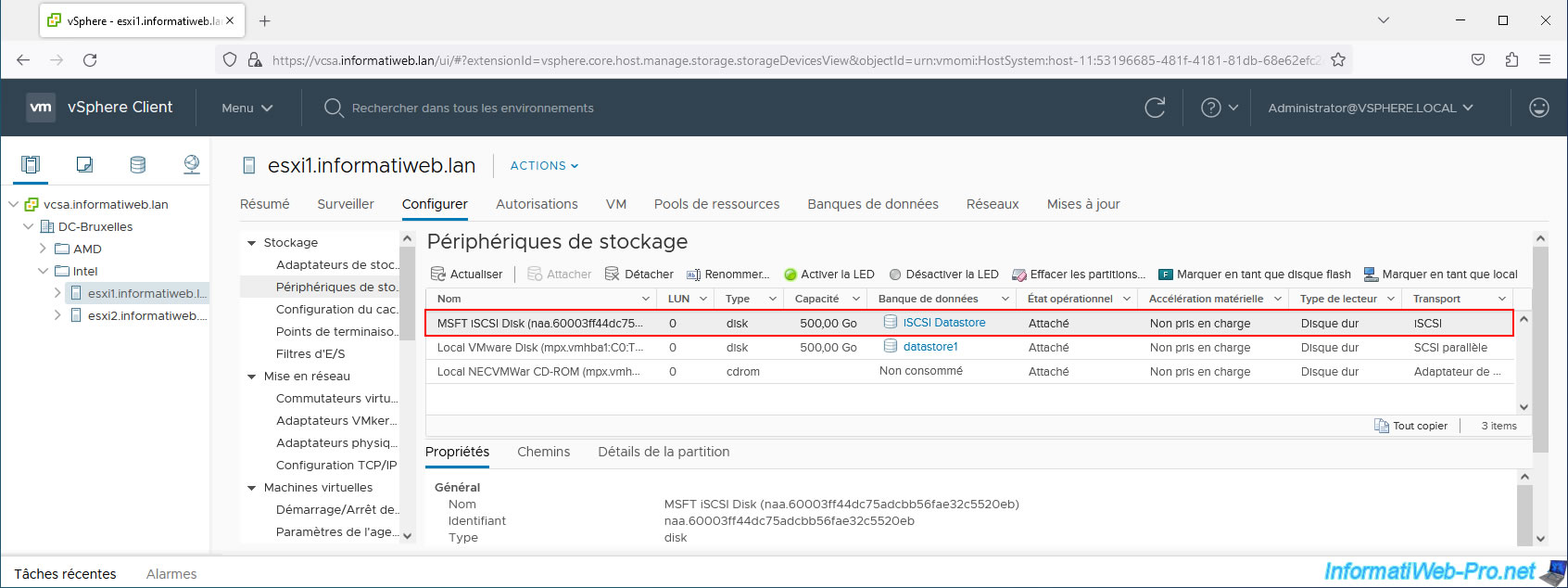
To generate a PDL state under VMware vSphere with an iSCSI server under Windows Server, simply remove permissions on the affected iSCSI target.
As you can see, in our case, our iSCSI target allows iSCSI initiators from our 2 VMware ESXi hosts (10.0.0.11 and 10.0.0.12).
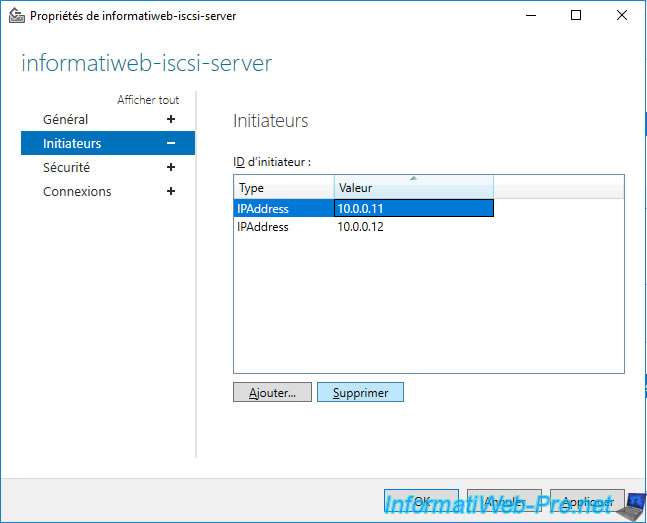
Once these initiators are removed from the list on your iSCSI target, click OK.
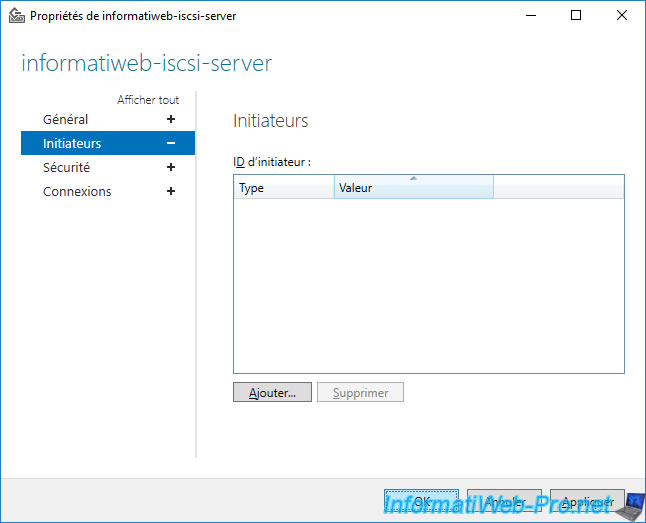
In the "vmkernel.log" log file mentioned above of your VMware ESXi host, you will see this message appear: "Permanently inaccessible device".
Additionally, you will also notice that the iSCSI disk has been automatically removed (ScsiDevice ... Device:naa... has been removed ...).
Bash
tail -f /var/log/vmkernel.log
Plain Text
2023-03-13T16:14:25.165Z cpu0:2097217)WARNING: ScsiDevice: 2170: Device :naa.60003ff44dc75adcbb56fae32c5520eb has been removed or is permanently inaccessible. 2023-03-13T16:14:25.165Z cpu0:2097217)ScsiDevice: 2185: Permanently inaccessible device :naa.60003ff44dc75adcbb56fae32c5520eb has no more open connections. It is now safe to unmount datastores (if any) and delete the device.
Source : Permanent Device Loss (PDL) and All-Paths-Down (APD) in vSphere 6.x and 7.x (2004684).
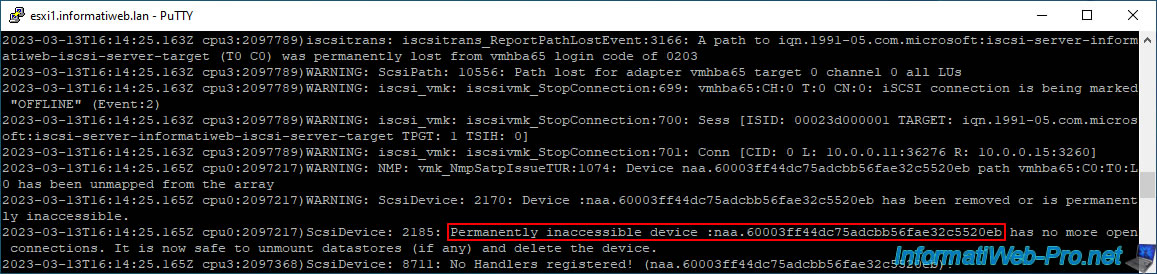
In the case of PDL status, in the VMware vSphere Client, you will again see that your iSCSI datastore is in "inaccessible" status.
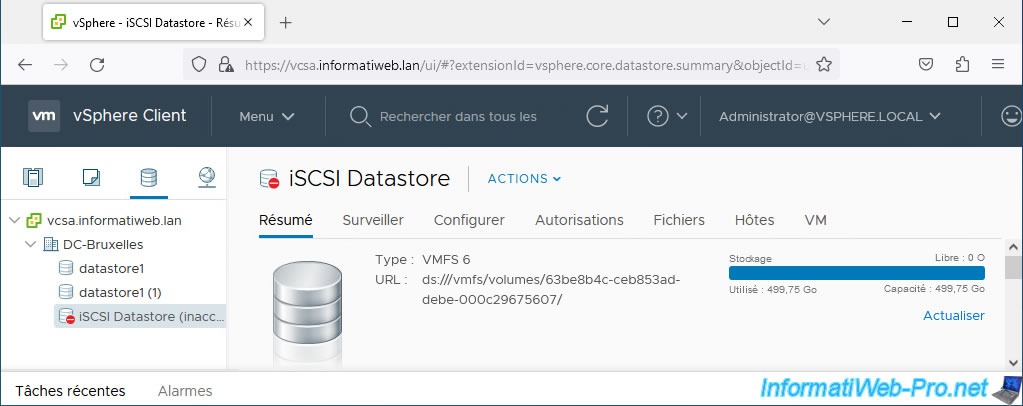
Because VMware vSphere considers storage in PDL state to be permanently inaccessible, the disk will disappear from your iSCSI controller.
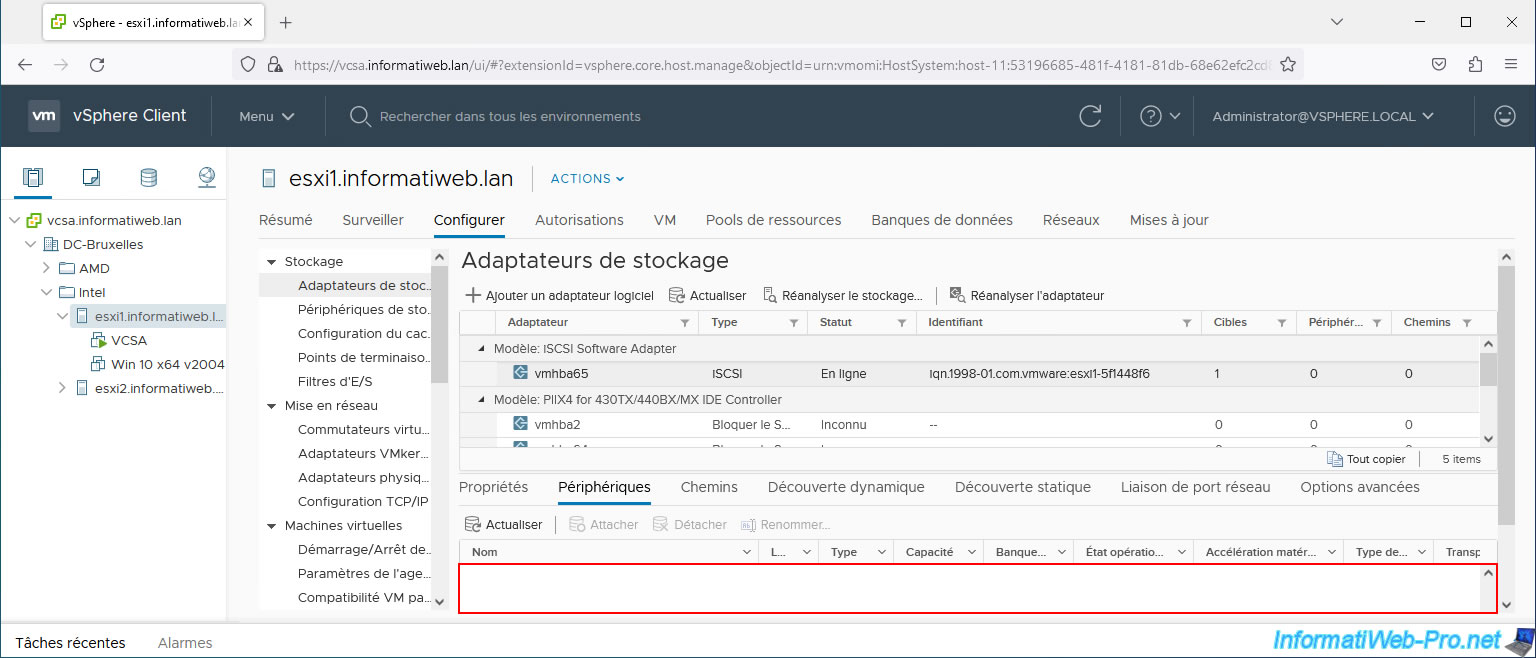
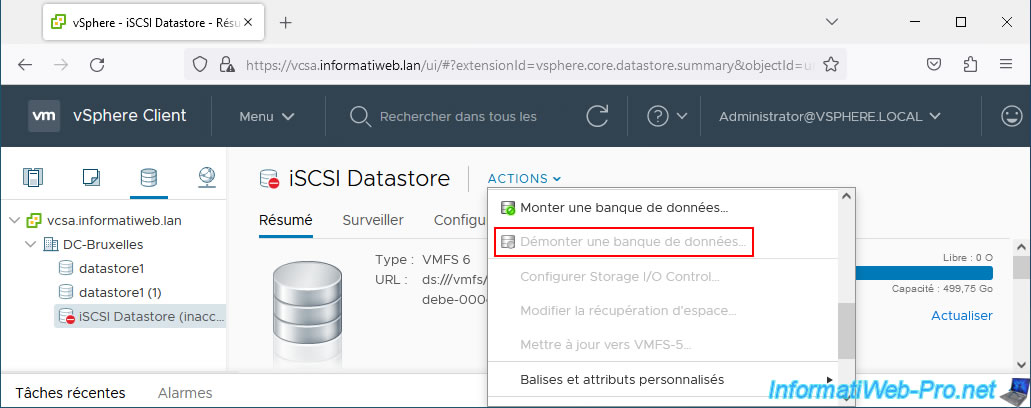
If you refer to the "Recovering from PDL Conditions" page in the VMware documentation, you will see that you are supposed to unmount the datastore to resolve a PDL state problem.
However, you will see that the "Unmount Datastore" option is grayed out on this iSCSI datastore.
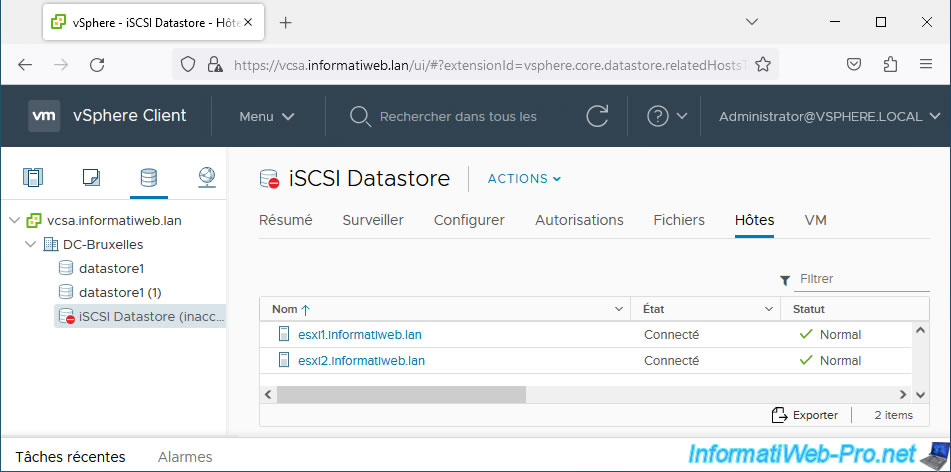
Go to the "Hosts" tab to find out which VMware ESXi hosts are using this iSCSI datastore.
To remove the iSCSI datastore concerned from your inventory, simply force the storage rescan on the hosts to which it is linked.
To do this, select a VMware ESXi host, go to "Configure -> Storage -> Storage Adapters", select the "iSCSI Software Adapter" and click: Rescan Storage.
Source : Datastore shows inaccessible state in vCenter.
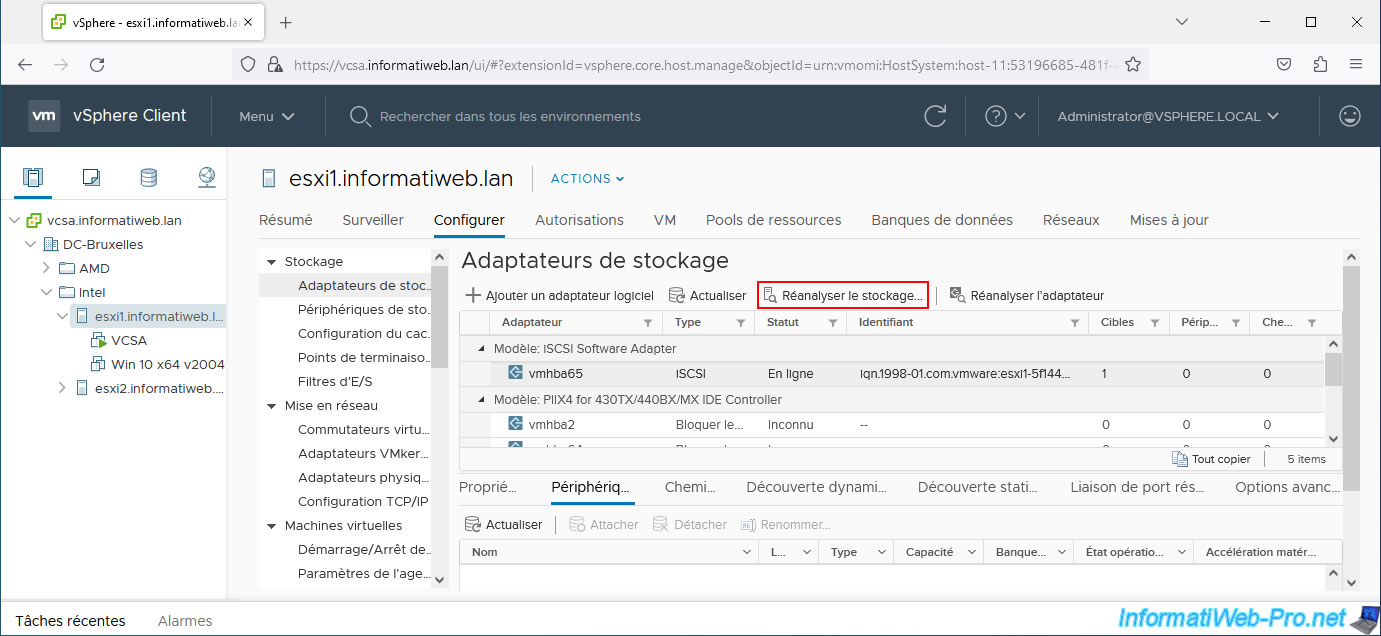
Leave the 2 boxes checked and click OK.

Do the same on the other hosts affected by the iSCSI datastore to disappear.
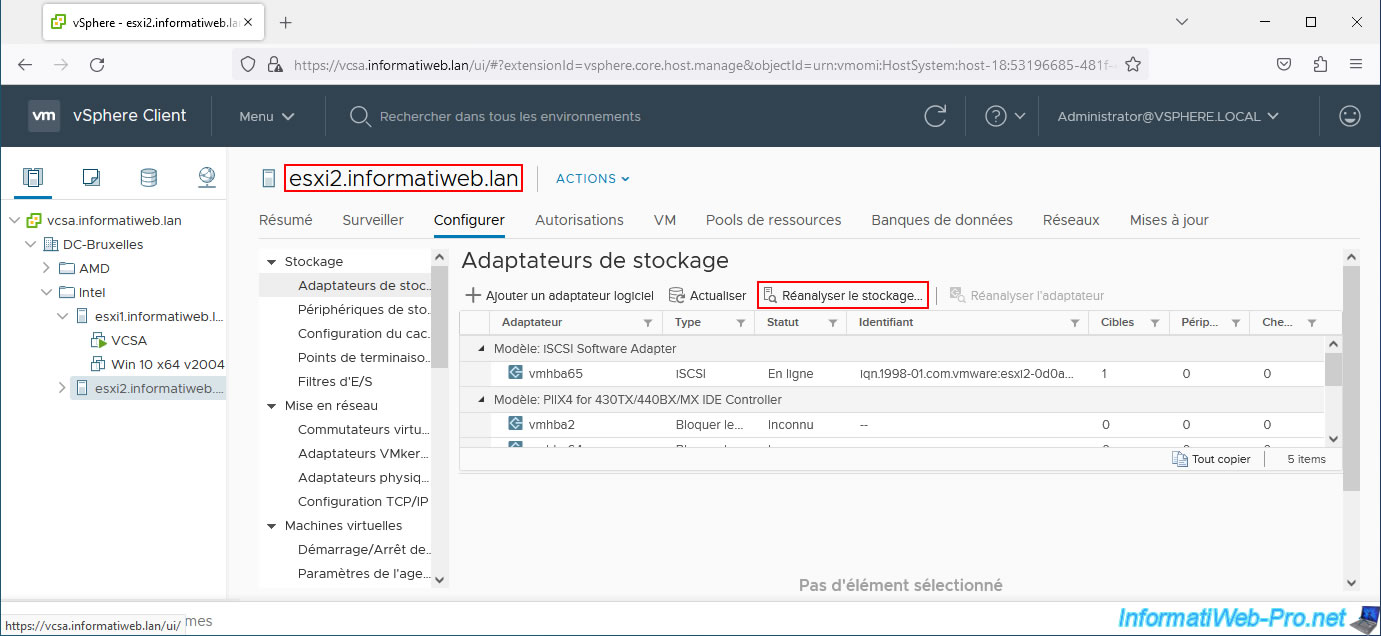
As expected, the iSCSI datastore that was inaccessible has disappeared from your inventory.
Share this tutorial
To see also
-

VMware 5/15/2024
VMware vSphere 6.7 - Add a physical disk to host
-
VMware 9/27/2024
VMware vSphere 6.7 - Array integration APIs (VAAI)
-

VMware 9/6/2024
VMware vSphere 6.7 - Configure port binding (iSCSI traffic)
-
VMware 6/13/2024
VMware vSphere 6.7 - Configure Virtual Flash (SSD cache)
You must be logged in to post a comment