Choose and configure the quorum of a failover cluster on Windows Server 2012 / 2012 R2
- Windows Server
- Clusters
- 19 July 2019 at 09:53 UTC
-

- 4/5

4. Priorities for failover
When you have only 2 nodes (servers) in a cluster, the clustered role will obviously switch to the other server when the server hosting that role goes down.
But, when you have at least 3 servers, it can be interesting to manage the failover priorities, as well as being able to automatically restore or not the different roles on this or that server.
Reason why we have just added a 3rd server to our cluster.
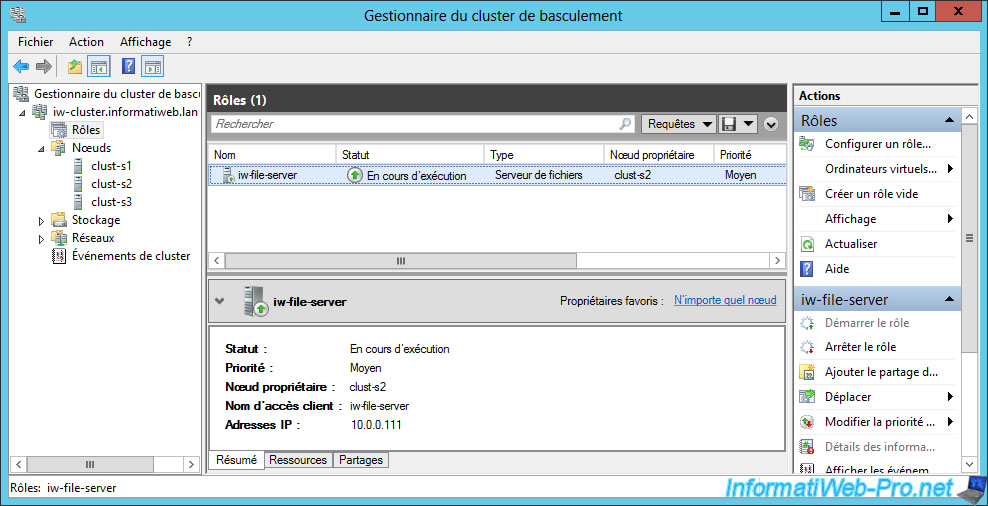
Right-click "Properties" on a clustered role.
In our case, the "iw-file-server" role type "File Server".
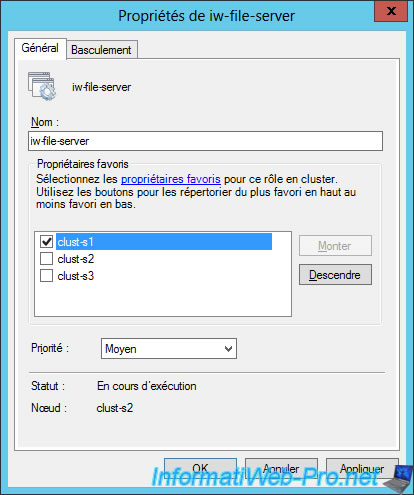
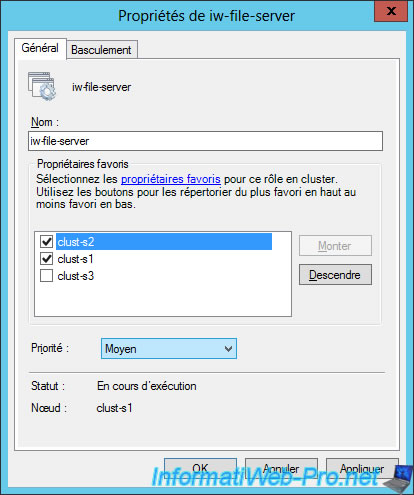
As you can see, you can choose one or more preferred owners for a clustered role.
If you choose a preferred owner, the role will be hosted by default on this server.
Then, in the event of a failure, this role will be restored automatically on this server (if the automatic restoration is activated in the tab "Failover" of this role) when he becomes online again.
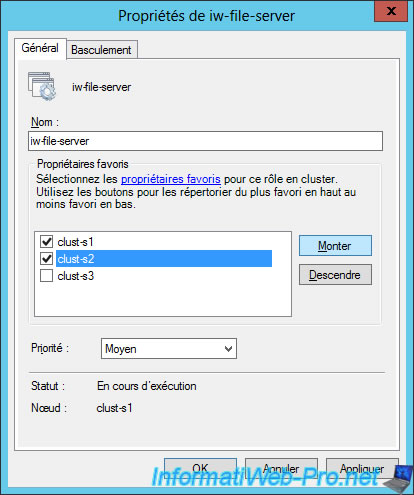
If you choose several preferred owners, you can manage the priority between them by checking them and then changing the priority order with the "Up" and "Down" buttons.
Note that changing the order for servers that are not checked in this list will have no effect.
When you close this window and reopen it, the order of unchecked servers will be the default one.
You can also specify a priority for this role and more specifically a startup priority.
In other words, it will be possible to indicate to a cluster that this or that role is more important and that it should therefore be started in priority compared to other less important roles.
Note : this priority is related to the role and not to the server selected in the list above. These are 2 completely different options.
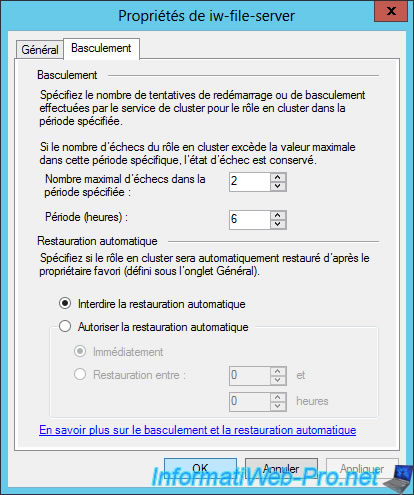
In the "Failover" tab, you will be able to define the maximum number of failures for the specified period.
Beyond this number of failures, the role will no longer start on the concerned server.
You can also enable or disable the automatic fallback of the role on one of the servers defined as preferred owners.
The automatic fallback allows you to restore the role to a preferred server so that it's hosted on the server that you consider to be more reliable and/or better performing for that role.
However, if you allow automatic fallback immediately, this can cause 2 service failures instead of one.
If all the servers in your cluster are the same (which should normally be the case), you can prohibit the automatic fallback.
Thus, there will be a break of the service only when the server hosting this service will fail.
If you really want to restore the role to a favorite server (for any reasons), we recommend that you schedule this automatic fallback at a time that is outside business hours (usually : during the night).
Thus, the role will work mainly on the favorite server of your cluster and the 2nd break will not disturb anyone.
5. Failover tests
5.1. Basic configuration
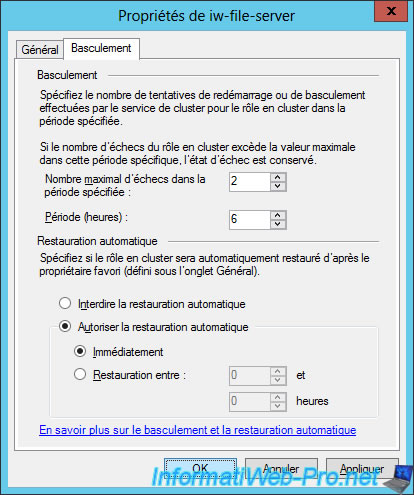
To test the failover of our role, we will allow immediate automatic restore.
Nevertheless, we don't recommend using this option in production for the reasons explained above.
Previously, we defined our server "clust-s2" as the preferred owner server.
To avoid starting on bad bases, we will move the role on this node.
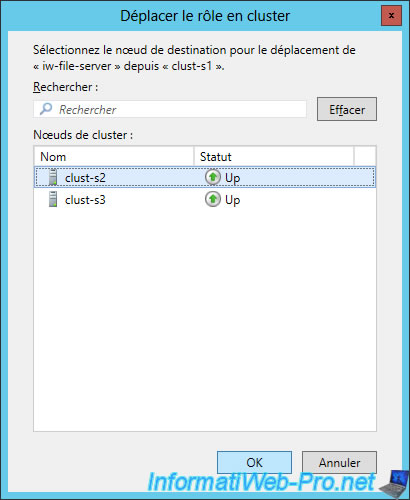
To do this, select the role to move and right-click "Move -> Select a node" on it.
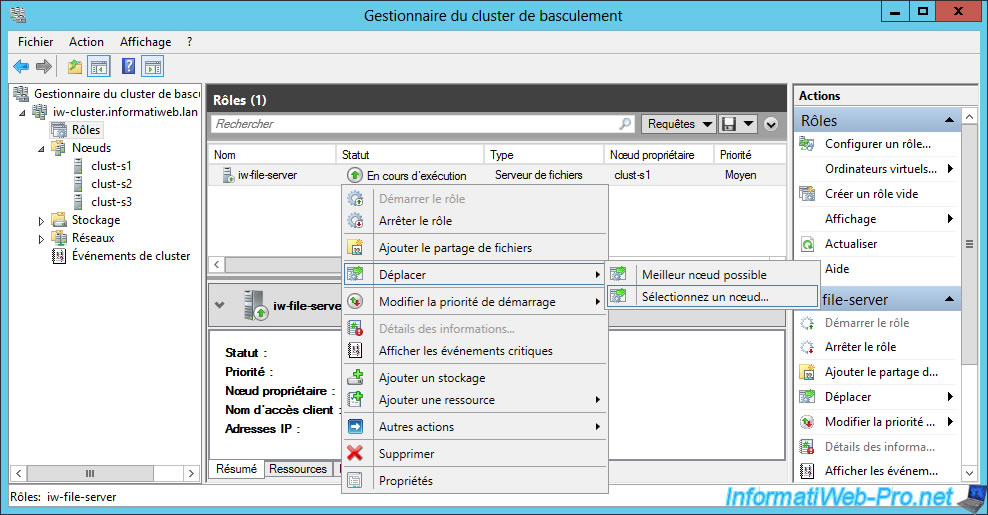
Select the "clust-s2" server.
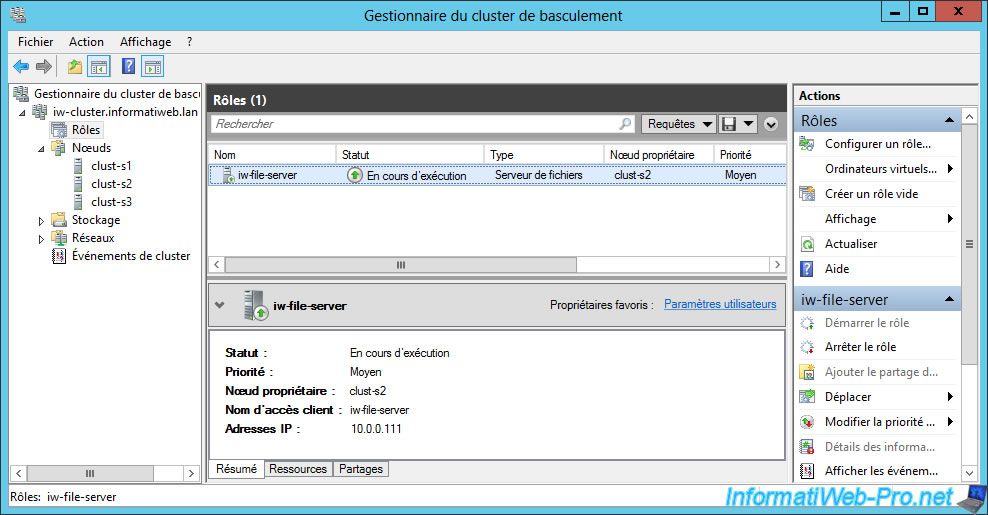
The role is now hosted by our "clust-s2" server.
5.2. Owner server down
We are shutting down the "clust-s2" server that is currently hosting our "File Server" role to simulate a server crash.
As you can see in the Failover Cluster Manager, the status of the role is currently pending.
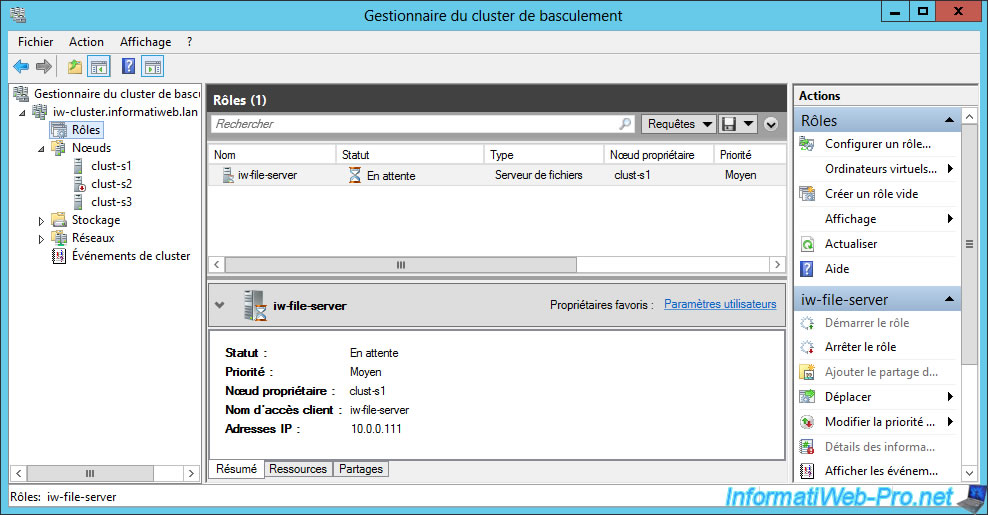
A few seconds later, the role was migrated to the second favorite owner server defined previously : clust-s1.
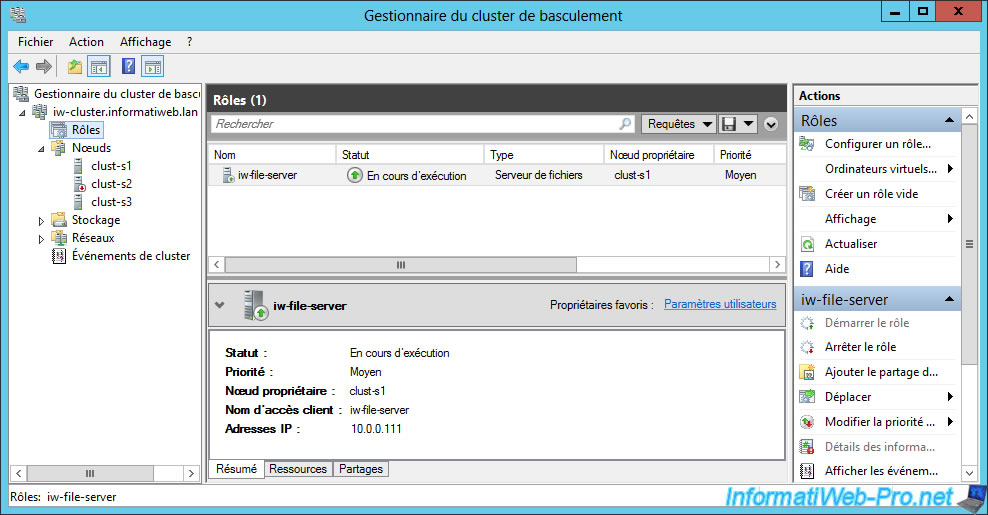
5.3. Restoring the role on the favorite owner
As mentioned before, we selected 2 favorite owners for our "File Server" role.
The "clust-s2" server had been indicated as a priority over "clust-s1".
Assuming that we had just repaired our server 2, we restart it and the failover cluster manager will detect it.
At this point, you will see that the state of server 2 will be "Bind in progress".
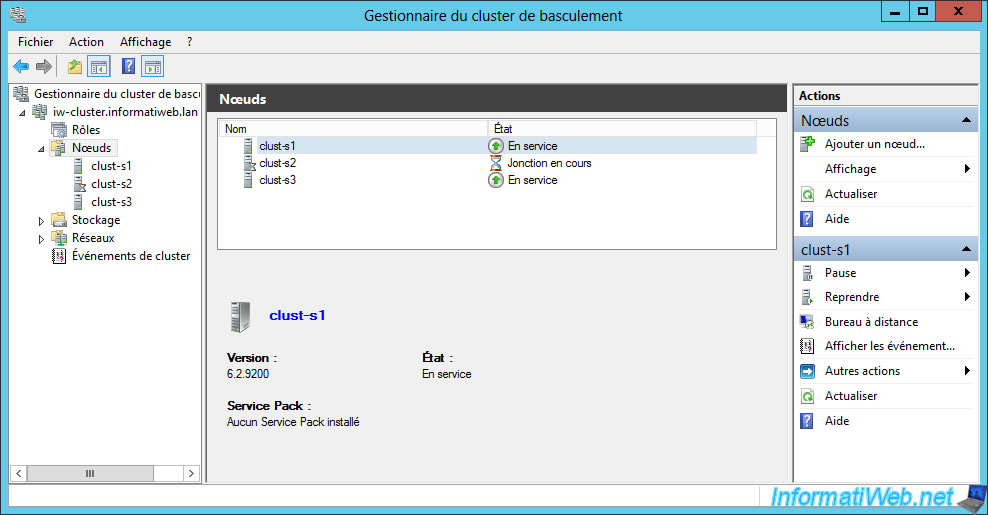
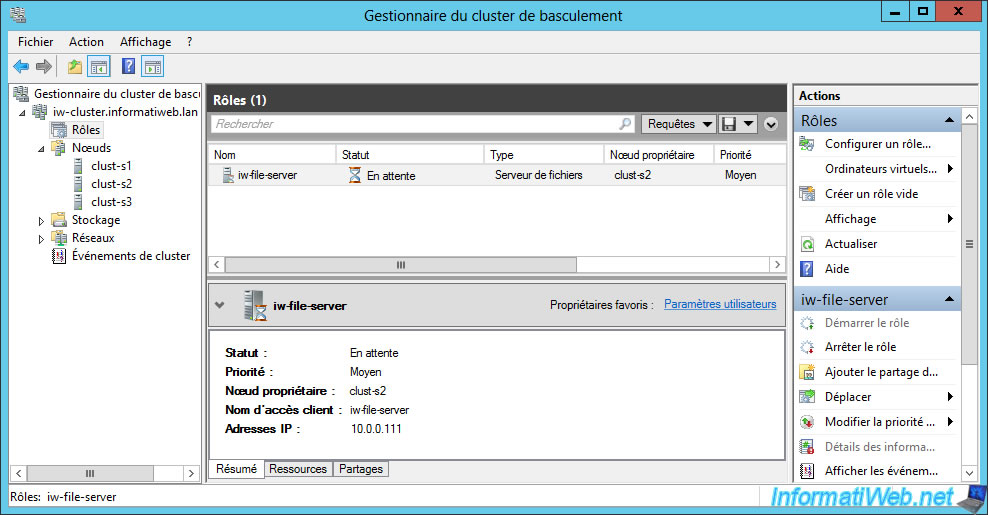
Since the immediate fallback (which we don't recommend in production) is enabled, the role will be restored automatically on the clust-s2 server (in our case).
This confirms what we explained earlier. And especially the fact that this causes 2 service breaks instead of one (one when the server crashes and another when the server is online again).
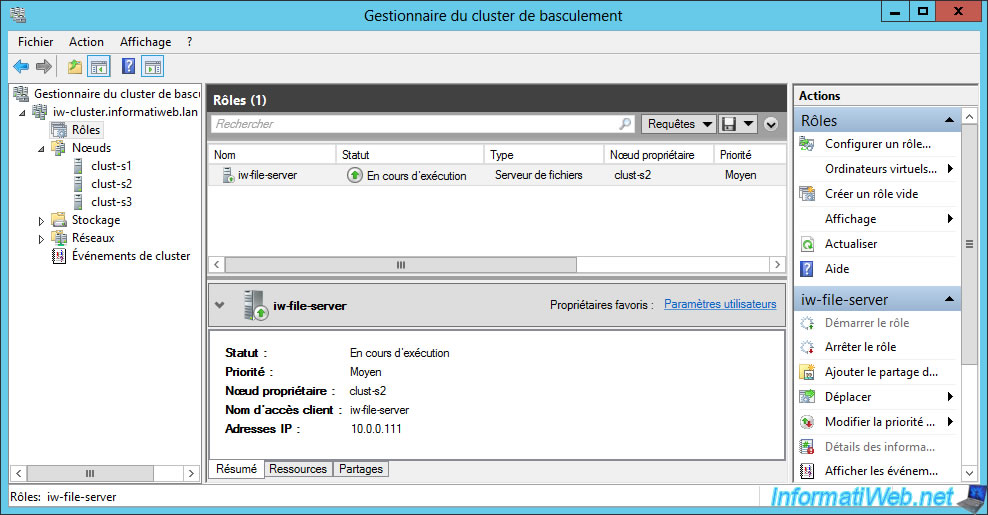
Now, our role is working again on the preferred priority owner : clust-s2.
Share this tutorial
To see also
-

Microsoft 11/29/2019
Hyper-V (WS 2012 R2 / WS 2016) - Create a failover cluster
-

Microsoft 12/6/2019
Hyper-V (WS 2012 R2 / WS 2016) - Disaster recovery (DR) with the Hyper-V cluster
-
Windows Server 7/7/2019
WS 2012 / 2012 R2 - Create a failover cluster of file servers
-

Windows Server 7/26/2019
WS 2012 R2 - How the dynamic witness of failover cluster works
No comment